
Confirmed keynote speakers for the Greeks 🇬🇷 in #AI 2025 Symposium in Athens, Greece 🤗
@alexdimakis.bsky.social @manoliskellis.bsky.social
www.greeksin.ai
11.04.2025 19:10
👍 10
🔁 1
💬 0
📌 1
Confirmed keynote speakers for the Greeks 🇬🇷 in #AI 2025 Symposium in Athens, Greece 🤗
@alexdimakis.bsky.social @manoliskellis.bsky.social
www.greeksin.ai
Excited to be part of Greeksin.ai

We are excited to release the OpenThinker2 reasoning models and data:
1. Outperforms DeepSeekR1-32B in reasoning.
2. Fully open source, open weights and open data (1M samples).
3. Post-trained only with SFT. RL post-training will likely further improve performance.
github.com/open-thought...
Please let us know what you find out.
Yes we have been thinking of doing this. DCLM 7B is a fully open model (full pre-training data and code open) and we could post-train it with open-thoughts.

Qwen32B. post-training data is open and available as openthoughts 114k huggingface.co/datasets/ope...

Performance of the best known Reasoning models on various Benchmarks. OpenThinker-32B matches the current state of the art.
We are releasing OpenThinker-32B, the best 32B reasoning model with open data. We match or outperform Deepseek-R1-32B (a closed data model) in reasoning benchmarks. Congrats to Negin and the whole Open Thoughts team.
github.com/open-thought...
Congratulations Constantine for this big effort for supporting Greek students.
for the 17k traces used in Berkeley Sky-T1, I joked that you could take 1000 student Berkeley course and give 17 homework problems to each student. On a more serious note universities are a great way to collect such data I think.
Our repo: github.com/open-thought...
Open code, Open reasoning data (114k and growing), Open weight models.
Please let us know if you want to participate in the Open Thoughts community effort. (2/n)
www.openthoughts.ai

What if we had the data that DeepSeek-R1 was post-trained on?
We announce Open Thoughts, an effort to create such open reasoning datasets. Using our data we trained Open Thinker 7B an open data model with performance very close to DeepSeekR1-7B distill. (1/n)
Thanks for featuring us Nathan !
We just did a crazy 48h sprint to create the best public reasoning dataset using Berkeley's Sky-T1, Curator and DeepSeek R1. We can get o1-Preview reasoning on a 32B model and 48x less data than Deepseek.
t.co/WO5UV2LZQM
Answer. Another way it could be done: Get data by teaching a 1000 student class and assign 17 homework problems. Side benefit: make $10M by charging $10K tuition.

The Berkeley Sky computing lab just trained a GPT-o1 level reasoning model, spending only $450 to create the instruction dataset. The data is 17K math and coding problems solved step by step. They created this dataset by prompting QwQ at $450 cost. Q: Impossible without distilling a bigger model?
Creating small specialized models is currently hard. Evaluation, post-training data curation and fine-tuning are tricky, and better tools are needed. Still, its good to go back to UNIX philosophy to inform our future architectures. (n/n)
This is related to the "Textbooks is all you need", but for narrow jobs like summarization, legalQA, and so on, as opposed to general-purpose small models. Research shows how to post-train using big models to create small models that are faster and outperform their big teachers in narrow tasks(6/n)
I believe that the best way to engineer AI systems will be to use post-training to specialize Llama small models into narrow focused jobs. 'Programming' specialized models can be done by creating post-training datasets created from internal data by prompting foundation models and distilling. (5/n)
Instead, I would like to make the case for Small Specialized Models following Unix philosophy:
1. Write programs that do one thing and do it well
2. Write programs to work together
3. Write programs to handle text streams, because that is a universal interface. Replace programs with AI models (4/n)
Monolithic AI systems are also extremely wasteful in terms of energy and cost: using GPT4o as a summarizer, fact checker, or user intent detector, reminds me of the first days of the big data wave, when people where spinning Hadoop clusters to process 1GB of data. (3/n)
This is not working very well. This monolith view of AI is in contrast to how we teach engineers to build systems. To build complex systems engineers create modular components. This makes systems reliable and helps teams to coordinate with specs that are easy to explain, engineer and evaluate. (2/n)

AI monoliths vs Unix Philosophy:
The case for small specialized AI models.
Current thinking is that AGI is coming, and one gigantic model will be able to solve everything. Current Agents are mostly prompts on one big model and prompt engineering is used for executing complex processes. (1/n)
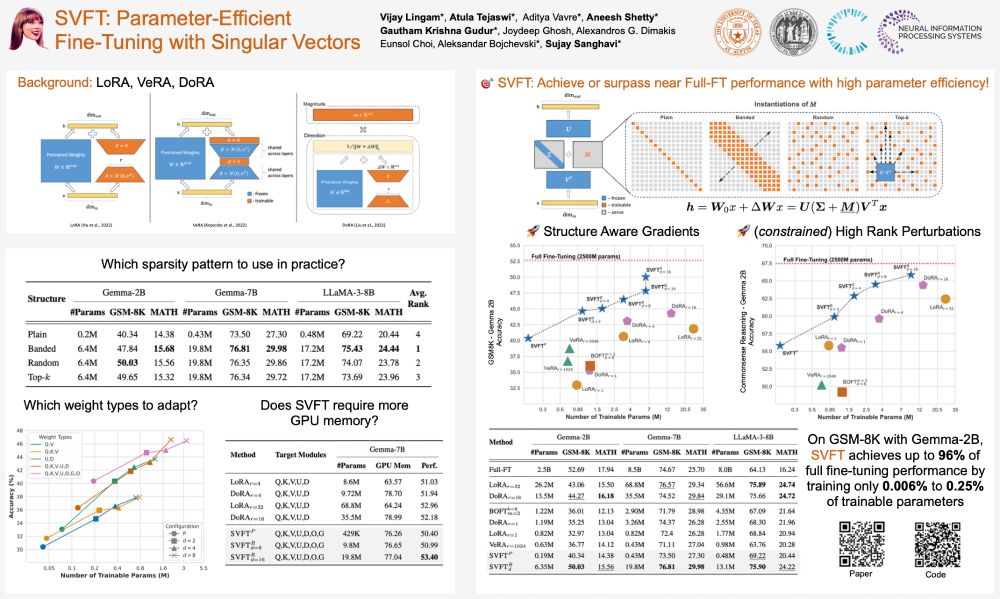
Missed out on #Swift tickets? No worries—swing by our #SVFT poster at #NeurIPS2024 and catch *real* headliners! 🎤💃🕺
📌Where: East Exhibit Hall A-C #2207, Poster Session 4 East
⏲️When: Thu 12 Dec, 4:30 PM - 7:30 PM PST
#AI #MachineLearning #PEFT #NeurIPS24
hello friends, I heard there is a party here?
hello world